
ドキュメント
コメント1:MooreDataは、MooreDataデータエンジニアリングプラットフォームの自動データエンジニアリングの思想を表しています。
コメント2:プラットフォームの最新情報については、
business@abaka.aiまでお問い合わせください。コメント3:私たちのプラットフォームを体験するには、MooreDataにログインしてください。
1. MooreDataプラットフォームが作成された理由
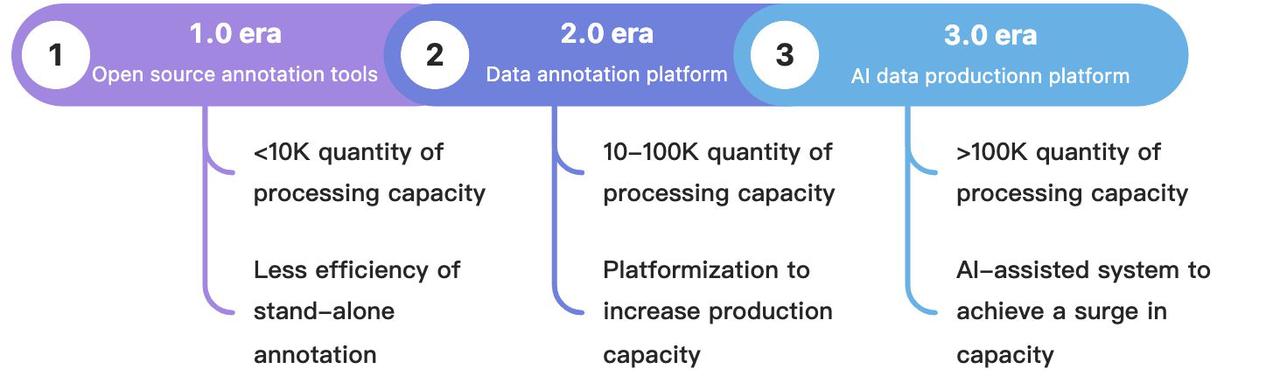
データアノテーションツールというと、labelmeやlabelImgなどのオープンソースソフトウェアを思い浮かべるかもしれません。オープンソースのアノテーションソフトウェアは、1.0時代(1万件の作業量)のデータ処理ニーズを満たすには十分です。
1.1 レベル1からレベル2へ
ニューラルネットワークの深化に伴い、AIモデルはモデルのトレーニング効果を向上させるためにより多くのデータ(10万件の作業量)を必要とし、データアノテーションは2.0時代に突入しました。従来のスタンドアロンのアノテーションツールでは、この時代のニーズにもはや応えることができません。そこで、データアノテーションプラットフォームが登場しました。プロセスベースのプラットフォーム運用を通じて、データ生産リンクのコラボレーションが実現され、クラウドソーシングモデルのサポートにより、データ生産能力の弾力的な拡大が可能になります。
1.2 レベル2からレベル3へ
AIが垂直産業に深く実装されるにつれて、データ処理の規模はさらに大きくなり、多くの場合10万件、あるいは100万件のオーダーになり、3.0時代が徐々に始まっています。この時代のデータは膨大であり、データ精度に対する要求も高くなっています。手動でのラベリングとレビューだけに頼っていては、この時代のニーズに応えることは困難です。そのため、AI支援システムをベースにした人間と機械の協調的なデータ生産プラットフォームが、この時代のニーズに応えるものとなりました。
AI分野の企業や機関に長期間にわたり高品質なデータサービスを提供する過程で、私たちは長年のデータプロジェクト管理の経験を活かし、一連の最適なソリューションをプラットフォームの管理モジュールに統合しました。同時に、より効率的なデータアノテーションツールを開発しました。究極のラベリング効率を追求するために、一部のシナリオではアノテーションツールにAIアルゴリズムを統合し、機械とラベラーが協力してデータアノテーションを完了できるようにしました。これは、3.0時代のデータプラットフォームのニーズにも応えるものです。
次に、ABAVAプラットフォームの便利な機能を見ていきましょう ;)
——ジャック・リン
2. 機能紹介
2.1 データアノテーションモジュール
画像アノテーションツール、点群アノテーションツール、テキストアноテーションツール、音声アノテーションツール、マルチモーダルアノテーションツールなど、一般的なデータタイプの処理ツールを提供しています。
2.1.1 画像注釈ツール
画像分類、キーポイント注釈、2D線注釈、2Dボックス注釈、2Dセマンティックセグメンテーション、直方体注釈、OCR注釈、マルチフレーム注釈などが含まれます。
2.1.2 点群注釈ツール
3Dボックス注釈、3Dセマンティックセグメンテーション、3Dレーンライン注釈、2D/3Dフュージョン注釈などが含まれます。


2.1.3 テキスト注釈ツール
NER固有表現認識、SPOテキストトリプレット注釈などが含まれます。


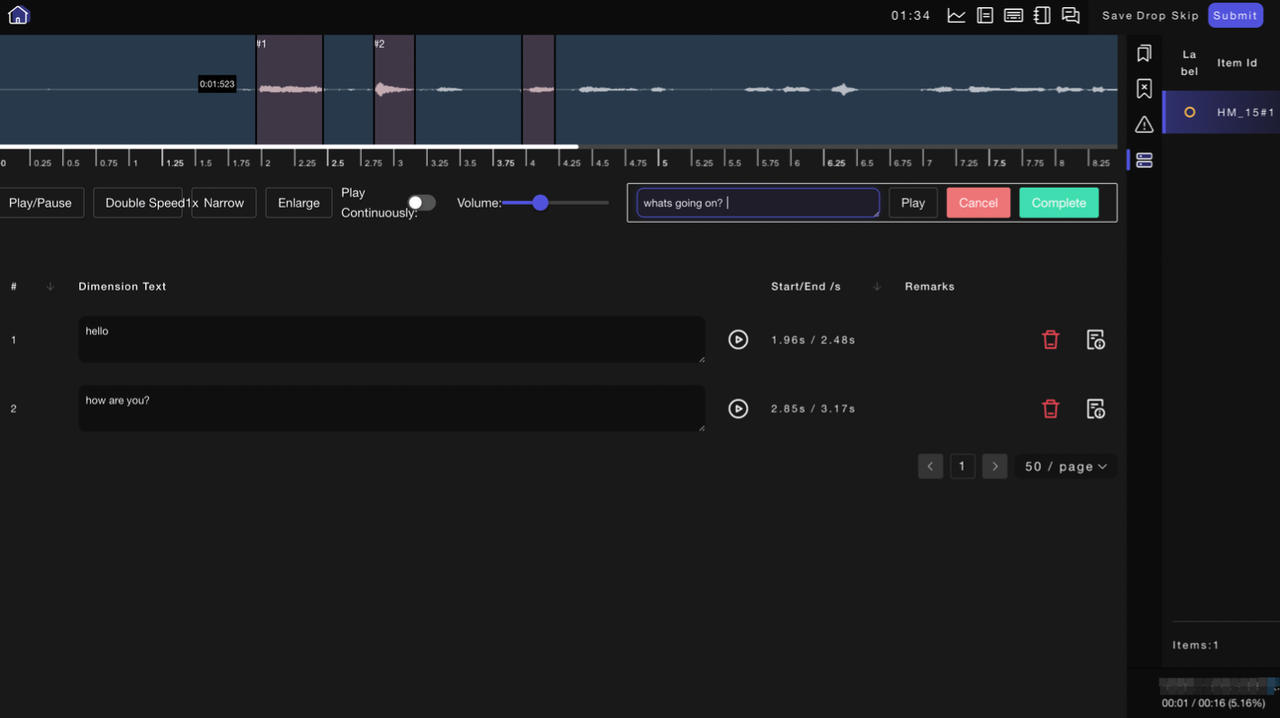
2.1.4 音声注釈ツール
ASR注釈、音素注釈などが含まれます。
2.1.5 ACL注釈ツール
4D注釈、ACLマルチモード注釈などをサポートしています。さらに、他の注釈ツールのカスタマイズ開発もサポートしています。ご要望がございましたら、business@abaka.aiまでお問い合わせください。
2.1.6 RLHF注釈ツール

2.2 プラットフォーム管理モジュール
2.2.1 2.データ生産のための最良のソリューション
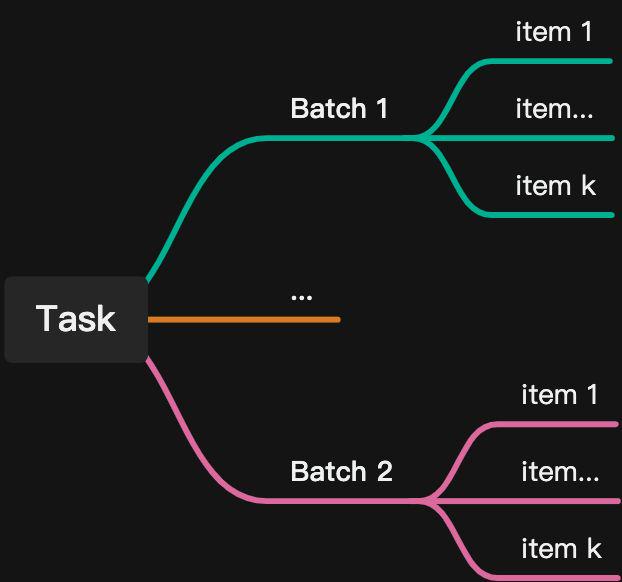
デリバリーはデータ生産のキーワードです。
ABAKA AIの最適なデータ生産ソリューションでは、バッチをデータデリバリーの最小単位と見なします。データタスクでは、各データバッチが同じプロセスに従ってデータ生産を行います。
以下のデータ生産プロセスを例にとると、4ノードのプロセスを作成しました。ノード1はラベリングプロセスを実行し、ノード2、3、および4はすべてレビュープロセスです。各ノードには1つのチームのみが参加します。ノード2をサプライヤーチームに割り当てて自己検査を完了させ、ノード3を自社で構築した品質検査チームに割り当てて完了させます。最後にノード4で、顧客に最終的な品質検査をさせます。
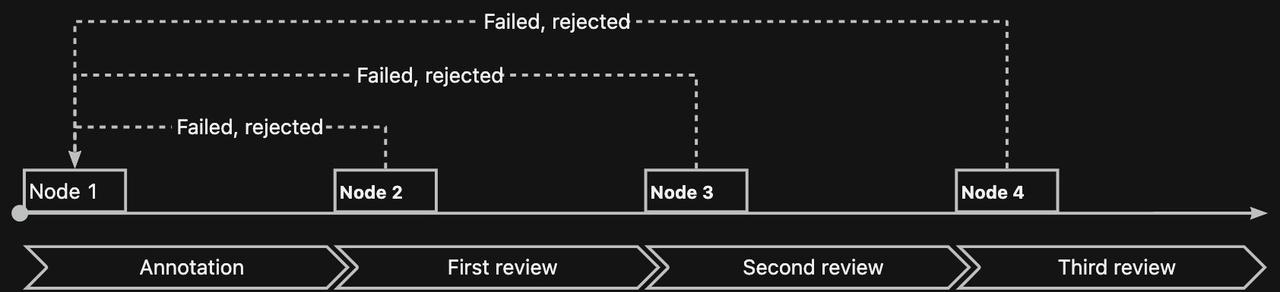
たとえば、このプロセスは会社の経費精算プロセスのようなものです。最初のノードは、経費精算申請書を提出するためのものです。 2番目のノードは上司がレビューするためのもので、合格しない場合は修正のために呼び戻され、合格した場合は3番目のノードに進みます。 3番目のノードはマネージャーによるレビューのためのもので、合格しない場合は修正のために呼び戻され、合格した場合は4番目のノードに進みます。 4番目のノードは最終ノードであり、合格すると払い戻しが行われ、合格しない場合は呼び戻されてプロセスが再開されます。
実際のニーズに応じてデータ生産のプロセステンプレートを選択できます。たとえば、3ノード(二重監査に対応)や5ノード(四重監査に対応)などです。
各ノードが終了すると、システムはノード上の動作データを自動的にカウントして分析します。このデータタスクのマネージャーとして、各ノードのサンプリング精度を視覚的に確認できます。さらに、詳細を表示することでデータバッチの多くの秘密を知ることもできます。これは、その後のデータ生産にとって非常に重要です。たとえば、バッチレポートでは、どのラベラーのラベリング精度が最も低いかを知ることができます。次に、ラベラーの注釈を続行する権限をキャンセルすることで、データの全体的な品質を向上させることができます。
2.2.2 プラットフォーム管理サブモジュール
ABAKA AIのプラットフォーム管理機能には、タスク管理機能モジュール、チーム管理機能モジュール、統計分析機能モジュールの3つの主要なサブモジュールが含まれています。
2.3 AIPower機能モジュール
MooreDataデータ管理プラットフォームには、注釈とレビューの効率を向上させることができる強力なシステム、つまりAIPower閉ループシステムがあります。「閉ループ」とは、自己反復して強化できるシステムです。
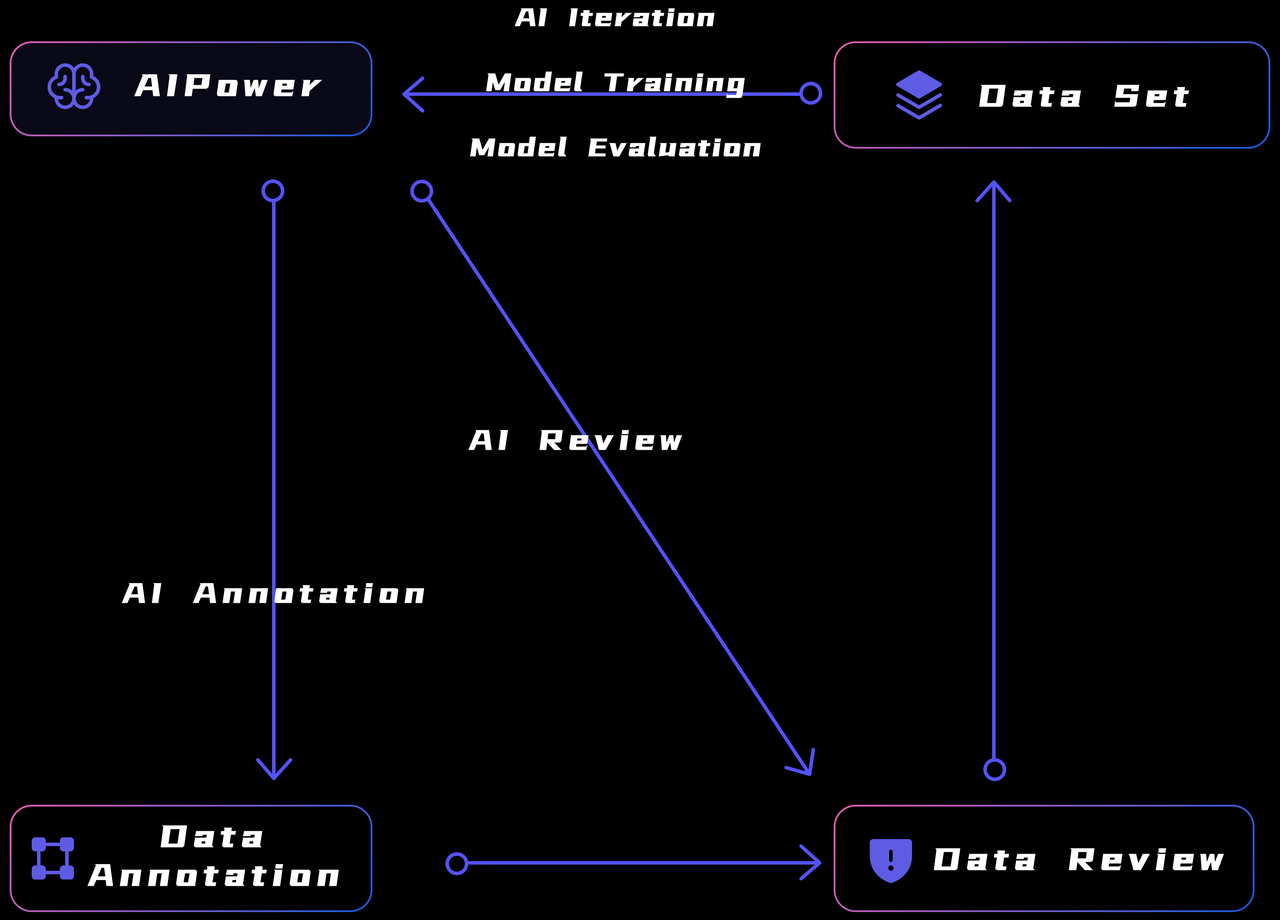
AIPowerモジュールは、AIインテリジェントラベリングやAIインテリジェントレビューなどのAI補助機能を提供できます。
- AI注釈:ラベリングが開始される前に、アルゴリズムはデータ全体のバッチに対してアルゴリズム推論プロセスを完了し、データ全体のバッチの事前ラベリング結果を取得します。
- AI監査:ラベリングが完了した後、アルゴリズムはデータ全体のバッチに対してアルゴリズム推論プロセスを完了し、実際のラベリング結果をアルゴリズムレビュー結果と比較して、エラーの可能性が高いデータをフィードバックします。
AIPowerモジュールは、新しく取得したデータセットを使用してアルゴリズムモデルの反復をサポートし、次のデータ生産プロセスでより正確なAI注釈およびAI監査機能を提供することもできます。
2.3.1 AI注釈機能
- AI事前ラベリング:ラベリングが開始される前に、アルゴリズムシステムはデータ全体のバッチのアルゴリズム推論プロセスを完了し、データ全体のバッチの事前ラベリング結果を取得します。これに基づいて、注釈者は手動で修正と微調整を行うだけで、効率を2〜10倍向上させることができます。
- AI共同ラベリング:ラベリングプロセス中に、ラベラーは少量のラベリングを完了し、その後、アルゴリズムがこのデータの残りのラベリング作業を完了し、ラベリング効率を2〜5倍向上させることができます。
2.3.2 AIレビュー機能
ラベリングが終了すると、アルゴリズムシステムはデータ全体のバッチのアルゴリズム推論プロセスを完了し、実際のラベリング結果をアルゴリズムレビュー結果と比較し、エラーの可能性が高いデータをレビュー担当者にフィードバックしてレビューすることで、エラー率を20%以上削減できます。
2.3.2.1 データプログラムを0から1まで管理する方法は?
MooreDataプラットフォームの科学的なデータ生産プロセス設計により、データプロジェクト管理の経験がないユーザーでも、高品質のデータ生産を簡単に管理および達成できます。
2.3.2.2 データサービスとツールを入手するにはどうすればよいですか?
自社開発のMooreDataプラットフォームは、SaaSおよびプライベート展開を通じて提供できます。
プライベート展開に関しては、business@abaka.aiに連絡先情報を残していただければ、専任のデータエキスパートが無料で1対1のコンサルテーションを提供します。
さらに、ACEサービスも提供できます。
